Using Tengwar with Lojban¶
Lojban using tengwar - why?¶
- Because the tengwar are just beautiful. As E.S.R. noticed, text written using poorly formed Fëanorian letters still look nicer than with latin letters. Moreover, the tengwar are easier to draw when handwriting;
- because as explained earlier, the Latin alphabet is too strongly related to western civilizations, and thus probably introduces some kind of cultural bias in Lojban. Lojban wants to be both logical and culturally neutral, the tengwar already are;
- because it is far more natural to write Lojban with a logical writing system. As we shall see later, the tengwar system inherently contains some main Lojban morphology rules, making Lojban easier to learn when it is written with tengwar.
I do insist on this last point. The Latin alphabet was initially chosen for Lojban for convenience issues, and because it was well-suited for computer use. But Lojban rules are not based on the latin alphabet. Roughly, Lojban is rather defined by the spoken form of words and utterances; the link between spoken and written forms of Lojban reduces to the one Lojban keyword: its audio-visual isomorphism.
Therefore, any other writing system than Latin can be used for Lojban, as long as there exist means to respect the Lojban rules regarding the writing of the language. We shall thus introduce how to use the tengwar system, along with all the necessary rules.
Using the tengwar to write Lojban¶
The easy part: consonants¶
The easiest mapping between the tengwar system and Lojban sounds is the one that deals with consonants. After reading the previous description, one can easily obtain the following map, following the most common usage:
| Dentals: | ||||||
| Unvoiced: |  |
- t |  |
- s | ||
| Voiced and nasal: |  |
- d |  |
- z |  |
- n |
| Labials: | ||||||
| Unvoiced: |  |
- p | 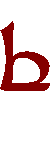 |
- f | ||
| Voiced and nasal: |  |
- b | (yet to be filled) | - j |  |
- m |
| The "universal sound": |  |
- l | ||||
Moreover, as the ancient Quenya modes didn’t have front-palatal consonants (at least not the ones necessary for Lojban), we shall build our Lojban mode according to other recent Tengwar modes, and thus respect the later meanings for several remaining tengwar: Series III will be used for front-palatal, and Series IV for back consonants.
| Unvoiced stops: | Voiced stops: | Unvoiced spirants: | ||||
| Front-palatal: | (allophonic with "t") | (allophonic with "d") |  |
- c | ||
| Back: |  |
- k |  |
- g |  |
- x |
So far, all is well, but “r”, “j” and “v” remain.
As “v” is the voiced counterpart of “f”, and we are following recent habits, it is natural to double the bow of tengwa formen, which leads to Grade 4, Series II (tengwa ampa).
For “j”, the task is tougher: we have both tengwa anga (III,2) and anca (III,5) used for the “j” sound in recent modes (where ancient modes seem not to have the “j” sound at all). However, the most logical choice is to double the bow of tengwa charma (III,3), which is already used for “c”, to obtain tengwa anca, which we shall use for “j”.
Finally, “r” can be either dry or trilled in Lojban, as long as it is recognized as a “rhotic” sound. Therefore, we shall keep for the moment both tengwa ôre and additional tengwa rómen as possible representations for “r”.
Thus the following complete consonant mapping table:
| The base tengwar, tengwar-lojban mapping | |||||
| I | II | III | IV | ||
| 1: | (t) |
(p) |
- | (k) |
|
| 2: | (d) |
(b) |
- | (g) |
|
| 3: | - | (f) |
(c) |
(x) |
|
| 4: | - |  (v) (v) |
 (j) (j) |
- | |
| 5: | (n) |
(m) |
- | - | |
| 6: |  (r) (r) |
- | - | - | |
| Additional *tengwar*, tengwar-lojban mapping | |||||
 (r) (r) |
- | (l) |
- | ||
| (s) |
 (s) (s) |
(z) |
 (z) (z) |
||
For the moment, we shall keep the inverted forms of tengwar silme and àze as “free variants” for “s” and “z”.
The beautiful part: vowels¶
Keeping the discussion on whether we need a full-letter writing or not for later, let’s see how to adapt the tehtar system to Lojban vowels.
First, Lojban’s structure emphasizes on CV phonemes (consonant, then
vowel) all over, therefore we shall have vowel tehtar put over the
preceding consonant.
Next, surprisingly, a check at the Lojban gismu and cmavo lists shows that in Lojban, “u” is more used than “o”. Therefore, the common rule for building Tengwar modes would have the tehta curl open to the right for “u” (and the other one for “o”), as in the Black Speech mode. Unfortunately, this clashes loudly with the actual popular use of this tehta for “o”, and with E.S.R.’s proposal. We thus shall keep the first proposal, but keeping in mind that it should have been the other way around.
However, the other Tengwar vowels can be used without restriction for Lojban, as they carry the same sounds. The only problematic one is the “y” vowel, for which the usual wet double-dot-below tehta is not relevant. Hopefully, we still have the rarely used one-dot-below tehta, which nicely represents the shwa (lojban’s “y”).
We thus get the following mapping:
| "a" | "e" | "i" | "o" | "u" | "y" |
 |
 |
 |
 |
 |
 |
The case of digits¶
There is nothing special to say about the use of digit tengwar for Lojban numbers. Proper use of digit tengwar is described here, and you might possibly notice how useful is the presence of duodecimal numberig where it can be used in many places in Lojban (for times, as main example).
However, for convenience purposes, we shall prefer the big-endian style for writing numbers (unless specified otherwise), unlike the common Elvish style.
Cleaning up¶
With the mapping table presented above, one is now ready to begin writing Lojban with Fëanorian letters. Let’s introduce a first sample:
~M jE `CjT8 d& 2#85% jR t% dErÈzY81E
(the last sample needs some tengwar fonts to display well)
Notice how the short carrier is used for vowels which do not have preceding consonants, and the long carrier for doubled vowels. Another way of doing for the doubled vowel would have been to double the tehta, which is exactly as unambiguous. Neither way should be preferred, leaving the choice of using one or another to the writer. I would however recommend the use of doubled tehtar, because the only cases of vowel doubling that occur in Lojban are “ii” and “uu”, for which the doubled tehta is shorter and easier to write, and moreover we are going to use the long carrier for other, though quite different, purposes shortly.
Now, the only remaining points to clear up before obtaining a complete Lojban mode are the Lojban apostrophe, stress, comma and period.
The apostrophe¶
The Lojban breathing has two possible Tengwar representations: the old-style tengwa halla and the more recent tengwa hyarmen.
While it is true that when choosing consonants we followed modern Tengwar rules, we shall however choose tengwa halla for the mandatory breathing. Firstly, because it is easier to write. Secondly, because it is visually less important than hyarmen, which is important as this sign does not convey a sound, and thus should not be as “large” as a full tengwa. And lastly, because tengwa hyarmen is too close in appearance to tengwa yanta, which will be used later to represent a full-letter vowel.
The stress (Lojban’s capital letters)¶
Written stress is not important when writing ordinary Lojban, because the grammar specifies where the stressing should occur when speaking. However, it is necessary to be able to represent peculiar stressing in the special case of writing proper names, because most names do not follow grammar rules.
There is no special sign to indicate stress in the known Tengwar system. However, as E.S.R. notices, there is no consonant doubling at all in Lojban; therefore, the consonant underbar, which looks like underlining, and otherwise used to indicate doubling of a consonant tengwa, should be used for stressing purposes.
Moreover, as well as Lojban is specifying that capitalisation is only necessary on the vowel which carries the stress (capitalisation of its surrounding consonants is optional), we shall specify that underlining is only necessary under the tengwa which carries the stressed tehta.
Morphology notes: The above rule is especially important when ve
have a “‘CVCY-‘” (consonant, then vowel, then consonant, then “y”, then
other) construct. Indeed, if it is the CVC part which is stressed,
underlining both tengwar would not only make the underdot of the
second tengwa difficult to see, but also would be understood as
stressing both CV and CY, which is ungrammatical in Lojban.
Additionnaly, it is a more “logical” way to stress written text; indeed,
only the first consonant of a stressed syllable is really involved in
the stressing, because it is where the initial breathing of the stress
takes place. The ending consonant, if any, is barely only used as a
closing sound, when it is not the opener of the next syllable.
The comma¶
It would have been more convenient to use tengwa hyarmen for Lojban’s apostrophe, and halla for the comma, for sure. But we just cannot use hyarmen, halla is already used, and alas there is no Tengwar sign that fits the purpose of Lojban’s comma at all.
Using the pusta might sound interesting; however, it is too proeminent, while the requested sign needs to be only slightly visible. And moreover, we shall use the pusta for other purposes later. The only solution here would be either to take an existing Tengwar sign and use it completely differently than what is was designed for, or simply to make up a new one.
Although E.S.R.’s proposal has adopted the latter, stating that a comma
is a good-looking tehta, there are more possibilities, such as using a
small circumflex accent under the tengwa preceding the break
(following the model of the tehta for y, by reusing a very rare
existing tehta), or to break the flow of letters when handwriting
(that is, omitting the letter link where the break should take place).
This latter idea should be preferred for very clean handwriting styles, which usually link all letters in a word: unlinking two adjacent tengwa would become obvious visually, and consequently by meaning. The former could be used with computers, where many already existing Tengwar fonts do not include a “comma” tehta (but do include a “circumflex-below” tehta).
I suggest leaving the choice to the Lojbanic Tengwar writer, as long as the same sign is used for a whole written text, and can be clearly understood as the explicit syllable breaker.
This approach is similar in philosophy to Lojban’s specification of the consonant buffer used when speaking consonant clusters. The sound used can vary, and it is only required to be recognizable as such, and not be confuseable with any other vowel.
The period (Lojban’s mandatory pause)¶
Here is a quote from The Complete Lojban Language:
Technically, the period is an optional reminder to the reader of a mandatory pause that is dictated by the rules of the language; because these rules are unambiguous, a missing period can be inferred from otherwise correct text. Periods are included only as an aid to the reader.
This is why we have a problem here. The Tengwar system doesn’t have a mandatory pause, except the pusta which unfortunately also means a break between sentences. In other words, the pusta carries way too much meaning than what would be necessary for a simple, Lojbanic, speech break.
However, the pusta is also the only tehta which could possibly suit our needs here. This is why I suggest introducing a lowered pusta which would be used for mid-sentence pauses, and a normal, medial pusta for breaks between utterances.
Special notes regarding the break between sentences¶
In Lojban, two distinct utterances are separated by “.i”, which would be transcribed, if using the Tengwar mode described so far, by a pusta followed by the short carrier over which a dot (vowel tehta for “i”) is applied. But, if we remember well, we also said that when a vowel has a tengwa before it, it should be placed as a tehta over it. So, what can be said about “.i”? If we consider the pusta as a possibly valid tengwa over which another tehta can be applied, we can just end up with a colon-like sign (dot-over-pusta) for the whole phoneme “.i”.
Incidentally, although it is not a coincidence, this is both what E.S.R. recommends for “.i” and what the original double pusta sign in the Tengwar system actually means.
Note that this “quirk” cannot be directly extended to other vowel-after-pusta cases, because whenever these occur in Lojban, the vowel is part of a cmavo diphtong, which we don’t want to break up by using two different ways of writing the vowels. However, it might prove interesting to use it for the first vowel in a proper name, which is always preceded by a break. A first experiment showed me that an initial short carrier in a word, which happens if the word begins with a vowel, is clear enough in meaning to omit safely any form of explicit break, but your mileage may vary.
A complete sample¶
Now that our Tengwar mode features every necessary sign, let’s try it with a sample Lojban text:
.uu la .alis. cu dasni le mi cavykosta .i .oi la’edi’u cu na pluka mi .i la .alis. cu sisku lenu mi mo cinmo
=~M jE º`CjT8º d& 2#85% jR t% dErÈzY81E - º`N`B jEœ`V2%œ`M d& 5# qjUzE t% - jE º`CjT8º d& i%8zU jR5& t% t^ d%5t^ (Go there for a picture)Please notice how the inverted silme is used for “si”. Similarly, inverted àze would be used if a tehta was to be applied.
Additional possible “features”¶
First, you might have noticed that there are several Tengwar signs that haven’t been used so far. Not that we actually should use the whole of them, still there are some tehtar which have obvious useful applications when writing Lojban.
Words ending in “s”¶
In Lojban, the only words that end in a consonant are names. But a vast majority of names actually end in “s” or “n”, because this is probably the most elegant way to transform an otherwise final vowel into a final vowel, then consonant phoneme. This process is described in Chapter 4, Section 8 of the Complete Lojban Language.
What is interesting here is that we have special signs in the Tengwar
system to indicate a final “s” consonant in a word: the various “s”
curls. Any CS (consonant, then “s”) final
construct could thus be turned into tengwa, then “s” curl;
additionnalliy, CVS could be turned into tengwa with tehta, then
“s” curl.
Allowing these extended rules, we can then write accordingly:
- "t#x#jTÂ¥" for "magalis",
- "c^6c$¢" for "xorxes",
- "t#61T5+" for "martins",
and so on… (Go there for a picture)
{kind=link}
In the very special case of a mode where all letters are written in full, the “s” should remain as a full-letter tengwa all the time, however.
End-of-text (Lojban’s “fa’o”)¶
Although the special Lojban word “fa’o” is not usually used for human communications (it was invented to be used as a sign for computer parsers to actually stop the parsing), it has already been used in its negated form (“fa’onai”) to indicate the intermediate “break” between parts of an episodic story.
Therefore, it might be interesting to use the horizontal curl tehta instead of a fully written “fa’o”, because this tehta fits the same purposes. However, as it is also common when writing Tengwar to put this sign at the beginning and end of written blocks, as it is far more appealing to the eye when used like this, a rigorous “fa’o”-to-tehta-curl might introduce some oddities in Tengwar representations: using a “fa’o” at the beginning of a Lojban text, for example, is sort of “counter productive”…
Change in topic (Lojban’s “ni’o”)¶
The horizontal curly tehta, as the horizontal one, is an indicator of ending of a written block. However, as its meaning is somewhat weaker, we shall use it instead of a fully written “ni’o”, because it both fits this purpose quite well and is visually quite more “obvious”.
Another example¶
To demonstrate the previous proposals, here is a yet more complete example than the one previously given.
me le lorxu .e le vanjba
.i lo lorxu noi xagji ku’o ca lenu viska loi vanjba noi dandu lo tricu cu djica lenu cpacu ra gi’e naka’e cpacu .i lego’i ca lenu darkla cu tavba’u fi vo’a fe lu lei jbari cu slari li’u
ni’o si’a so’i remna noi na’eka’e xagygau lei cuntu ki’u loka ruble cu fuzysku le tcini
t$ jR jY6c& º`V jR r#5fw#- jY jY6c& 5^`B c#xf% zUœ`N d# jR5& r%8zE j^`B r#5fw# 5^`B 2#52& jY 16Td& d& 2f%d# jR5& dqEd& 6E x%œ`V 5#zEœ`V dqEd& - jRx^œ`B d# jR5& 2#6zjE d& 1Erw#œ`M eG r^œ`C eF jU jR`B jw#6T d& 8jE6T jTœ`M
Á i%œ`C iYœ`B 6Rt5# 5^`B 5#œ`VzEœ`V c#xÈx#`M jR`B d&51U zTœ`M jYzE 6UwjR d& eJkÉ8zU jR 1d%5% Â
Writing vowels in full¶
For two reasons, it is desireable to be able to write Lojban with full-letter Tengwar vowels.
The first one is that for rapid translations and/or character-cell
computer displays, a one-to-one mapping between Latin and Tengwar signs
is much easier than computing all the different tengwa+tehta
combinations. Moreover, many fonts allow for only 256 different
characters, and fitting all CV constructs in such a table doesn’t
leave space for other possibly useful chars.
The second reason is related to the consistency of sign-to-spoken
correspondance. Indeed, for isolated vowels (mainly selma’o Y and
other words starting with a vowel), a single sign, rather than the short
carrier with a tehta, is easier to write. Moreover, and this is more
important, when writing Lojban diphtongs, it is far more preferable to
group the vowels forming the diphtong rather than, in one case, mapping
CVV into CV+V (tengwa+tehta, then short carrier and tehta),
or in another, mapping VV into two short carriers with tehtar.
Before going any further with these morphology considerations, let’s have a look on what tengwar to choose for vowels.
The obvious choice is to use the mode of Beleriand, because it features almost all the vowels we need, ans has already been used in most Tengwar modes for this purpose. Here is the already existing correspondance map we shall use:
| "a" | "e" | "i" | "o" |
 |
 |
 |
 |
You may have noticed that “u” and “y” are missing. This is because the correponding Lojban sounds didn’t exist in the Elvish tongue of Beleriand, and the two signs used for Sindarin “u” and “y” are not representative of the sounds we need.
For the case of “u”, which sounds like “w” in diphtongs, we still have tengwar vala and wilya (nr. 22 and 24), which stand for consonant “w” in many modes. As the tengwa wilya is somewhat older than vala, and that it follows the ancient rules of using Series IV for rounded backward consonants, we shall use tengwa vala for “u” in diphtongs, and by extension in other forms of standalone “u” vowels.
However, “y” still remains. E.S.R. proposed using the long carrier without any tehta for it; it is a good choice, as the schwa (the “y” sound) is a neutral vowel, and thus can be said to be a “genderless vowel not yet specialized”, for which a vowel carrier without tehta is appropriate (and as the short carrier is already taken for “i”, we can only choose the long one).
We can now introduce a full mapping table for vowels:
| "a" | "e" | "i" | "o" | "u" | "y" |
|
|
|
|
 |
 |
You may also wonder if introducing the short carrier for a full-letter vowel does not clash with its possible use as an isolated vowel carrier. Hopefully, the short carrier was only used before to write isolated vowels, and is therefore made obsolete by the even presence of full-letter vowels for this case.
The same applies for the long carrier, which was used for Lojban “uu” and “ii”. Fortunately, if we introduce a rule where diphtongs are written using a full-letter vowel tengwa with a tehta over it, then the usefulness of the long carrier as an actual “long carrier” is not needed any more: “uu” and “ii” will just be written as vala+backward hook and short carrier+dot.
A final example for this part¶
Now that our compound Lojban mode is complete, let’s write a final representation for the first example given:
.uu la .alis. cu dasni le mi cavykosta .i .oi la’edi’u cu na pluka mi .i la .alis. cu sisku lenu mi mo cinmo
= yU jE º]jT¥º d& 2#85% jR t% dErÈzY81E - ºhT jEœl2%œy d& 5# qjUzE t% - jE º]jT¥º d& i%8zU jR5& t% t^ d%5t^ Â(Go there for a picture)
{kind=link}
A final point about vowels and other special signs¶
It is very important to realize that we now have three distinct modes for using the Tengwar system for Lojban.
- Firstly, we defined a mode where vowels are set over the preceeding consonant tengwa, and if not possible, over the short or long carrier;
- secondly, we defined a mode where vowels are written completely in full, where the Tengwar text is written without vowel tehtar at all;
- lastly, we extended the first mode (and deprecated it) in favour of a mode where full-letter vowels are mixed with tehtar for morphology purposes.
Although the first and second modes respect the “audio-visual isomorphism” rule of Lojban to the foot of its letter, the third one only follows it up to its spirit, and requires some little more thought when writing (and allows different writings for the same sequence of sounds in the very special case of names). However, as we shall see later, this later mode should be preferred for various reasons (mainly elegance and practicalness).
Deeper explanation: it is important to remember that this famous audio-visual isomorphism means that the spoken forms of a single written text should all have the same meaning, and the same meaning as the text, and also means that all the written forms of a single spoken utterance should have the same meaning, and the same meaning as the utterance. It does not strictly specify that all spoken forms of a single text should be the same, neither that all written forms of an utterance should be the same, just that they should have the same meaning. Hopefully, all three Tengwar modes described above respect this last point.
You may now jump to the next part …