Ever since 2010, I have studied the “meta” of software, by studying (and thinking about) the continued dialogue between programming language designers, computer designers, and programmers.
The following constitutes a snapshot of my current thinking.
Epistemological context
During the period 2008-2012, I was requested to help design&build programming tools for a proposed new microprocessor architecture. The details of said architecture do not matter here; what is interesting is that folk in that research group had the following idea:
- their architecture had many design knobs, and they didn’t know what position to choose in the design spectrum.
- so instead they decided they would abstract over all the possible design points, and spell out a model that describes them all.
- then they asked me to make programming tools that work over all the possible-but-not-yet-existing platforms described by that model.
Of note, I did not know this is what was asked of me at the beginning. I only figured it out towards the end.
The more remarkable aspect is that these researchers did not understand that this is what they were doing either.
Instead, what they were saying they were doing was:
- “we’re trying to invent a microprocessor.”
- “we specified a virtual machine for it and we implemented an emulator.”
- “it’s not finished.” (what they meant, but did not understand, is that too many design points were remaining open; plus the emulator was always changing and incomplete.)
- “please make a C compiler happen.”
What wasn’t clear to me at the time, nor to them, is that the particular design choices that go into a hardware microprocessor have heavy implications on the design and implementation of programming tools.
In particular, we found that when we change the hardware too much, it becomes hard to design efficient algorithms using existing languages, even if a compiler/toolchain exists.
So the particular project above wasn’t exactly successful (there was no hardware, and too many knobs were left unspecified), I explained so much in the preface to my doctoral thesis, also later ranted about the arrogance of such a scientific premise in the context of software history, then that project stopped.
But the insight about this “software meta” was still open: why are programming languages so intimately linked to hardware architectures?
I continued studying this question throughout the period 2012-2018, and it remains a hobby to this day.
❦❦❦
As I started my own “research program” on this topic, I spent time to scrutinize the vocabulary in use in the field and in the academic community.
It turns out, computer architecture practitioners really like working with models, because models are cheaper to work with than real hardware. After all, there’s never enough money in academia. But then, they also ask computer scientists and programmers to work with them, and everyone is then working in model-land, with emulators and simulators.
To simplify and satirize the situation, it is as if millions of euros were spent finding solutions to important social and mechanical problems by analyzing and programming the PICO-8 fantasy console.
Everyone says “my architecture, and my software for it, do things” and nods politely to each other, without ever acknowledging that there’s no way for anyone to hold an artifact in their hands that works like what their model predicts.
By far, the most insidious intellectual fallacy I found in that environment is that enough scientists confuse specification and description. They design a model to describe something and make predictions about it (that’s fine), then they change their model and say “we can build a physical system that follows this new model”. The latter is scientific nonsense.
Changing a descriptive model is not an act of design. It does not “create” anything in the real world. If one is lucky, the new model can describe something else that happens to exist already. If one is unlucky, the new model describes nothing that exists; that new model is useless and pointless.
That was my first self-guided foray in computing epistemology: modeling and specification (& system design) are two fundamentally different intellectual activities.
I held my first public talk about this in 2013.

Boundary of functional semantics: syntactic variance
One of the major obstacles I encountered on my way to the above insight was the existence of Haskell (the programming language), and a community of peers who were very strong Haskell advocates and practitioners.
Haskell presented an obstacle because Haskell has denotational semantics: a machine-independent model of what Haskell programs “do” when they run. It is machine-independent because it does not require the decomposition of a computation into hardware steps to predict the result.
At face value, back then, I was thinking that Haskell can be used to specify programs and their behavior in the abstract, but also simultaneously their behavior in the real world. It felt, to me, as if Haskell’s descriptive abstract model somehow had “specification power” over the physical world.
As long as was stuck there, I was not able to see the difference between description and specification.
My breakthrough happened when I saw these three specifications of an integer sort function:
f :: [Int] -> [Int]
f = map sum . transpose . transpose .
map (flip replicate 1)
f (p:xs) = f [ y | y <- xs, y < p ]
++ [p] ++
f [ y | y <- xs, y >= p ]
f (h:tl) = c $ foldl g (h, []) tl
where
c (s, r) = s : f r
g (s, r) x | x < s = (x, s:r)
| otherwise = (s, x:r)
(The first one is an implementation of bead sort, the second one is a quicksort, and the third one is an insertion sort.)
In Haskell’s denotational semantics, these three implementations are functionally equivalent: we could swap one for another in any program without change in semantics.
And then, because Haskell’s denotational semantics only provides knowledge about functional semantics, this means that there is no difference, under that model, between these three implementations.
And yet, these three implementations exist, and they differ from each other. Why would a programmer ever want to choose one over another?
There was clearly something that mattered in the expression of each of these three functions, but that the denotational semantics model was not able to represent.
❦❦❦
That “special something”, of course, had something to do with run-time performance.
In casual conversations, and some less-than-stellar writeups by fellow practitioners, I often heard the following theory: since the model predicts these functions are equivalent, “it should be possible” to make an optimizing compiler which, given one of them, automatically derives the others, to choose the best one given a target hardware platform.
The suggestion that was made to me was that to build software in general, it should be good enough to invent one program that works in an abstract model, and then build “sufficiently clever” compilers that take care of translating that program optimally to any target hardware without additional programmer input.
And so I investigated this. Could it be true? Maybe these differences above were just inconsequential noise?
Alas for my fellow practitioners, I was vindicated by the discovery of the following article, which cemented my distrust of descriptive semantic models forever: Jeroen Voeten, On the fundamental limitations of transformational design, ACM Transactions on Design Automation of Electronic Systems, Volume 6, Issue 4, October 2001, pp 533–552, DOI 10.1145/502175.502181.

In short, Jeroen V. demonstrated mathematically that if a specification system is sufficiently general (like Haskell’s semantics), the automatic derivation of all functionally equivalent specifications from a given starting point is undecidable.
So much for universally general optimizing compilers.
In other words, the choice made by programmers for one implementation over another, when they are functionally equivalent, matters somehow in a way that cannot be described in the model of their functional semantics.
In hindsight, I recognize that sounds obvious, almost tautological. Yet, virtually all of my peers at the time did not believe me at first, and were annoyed that my statements could risk their sources of funding.
Abstract Machine Models
Introduction
From there, I focused on the following: “what’s in the mind of programmers, when they choose one way of doing things over another that’s functionally equivalent?”
The one thing that was clear from the start, is that most programmers “simulate” the behavior of their program in their mind, to predict how the program will behave at run-time.
As we’ve determined above, that simulation does not happen in the functional model of the programming language.
Meanwhile, I knew from my teaching practice that nobody really understands hardware computers, and so this mental simulation was also not happening with a model of a hardware platform. In fact, I’ve found that folk would rather not think about hardware at all, and thankfully so: this made it possible, over and over, to port software from one hardware platform to another, without rewriting the software.
This meant that all programmers are able to construct a somewhat abstract model of their computer in their mind, but not so abstract that it becomes purely functional.
That is when I coined the phrase abstract machine model (AMM), and it became the anchor of my subsequent study.
I then made a prediction of what AMMs would and would not include:
AMMs extend functional models with models/intuition of extra-functional behavior, including:
- Time to result.
- Memory usage.
- Available I/O primitives.
- Interfaces with debuggers and tracing facilities.
- Throughput/latency of operations.
- Jitter of operations.
- Energy expenditure.
AMMs have compositional semantics for programs: programmers want to predict what’s the behavior of combining two sub-programs, when they have prior intuition about each sub-program.
So AMMs must contain “program combining operators” (e.g. sequencing, parallel execution, process duplication) and allow extra-functional predictions about the results of these operators.
AMMs do not commonly include low-level details such as wiring topology, specific processor counts, specific memory sizes, instruction set architecture (ISA), etc.
I announced this project to my peers early in 2014, at the Netherlands Functional Programming Day workshop (slides).

❦❦❦
As I soon discovered, I was not the first with an interest to create an inventory of abstract machine models.
The following article, too, shaped my thinking durably: Peter van Emde Boas, Handbook of theoretical computer science (vol. A), chapter Machine models and simulations, p. 1-66, MIT Press, 1990, ISBN 0-444-88071-2. (Usually available in university libraries, contact me otherwise.)

In there, Peter v. E.-B. identified that the study of algorithmic complexity, which is about predicting execution time of programs, depends on particular properties of the target computer. He then went on to classify various machine models that associate different algorithmic complexities to the same algorithms.
This was, incidentally, the analysis that formalized the difference between RAMs, used to predict the behavior of simple sequential programs and P-RAMs, used to predict the behavior of programs run on multiprocessors with shared memory. These two have since become two staples of computer science curricula around the world.
The author also identified MIMD-RAM, a model of networked machines with a dynamically adjustable number of processors, which he demonstrated to be yet a separate class.
Yet, Peter v. E.-B. was strictly interested in execution runtime, estimated as a count of basic operations known to take fixed amount of time in the physical world, and memory usage.
There was nothing there to be found about the other dimensions of extra-functional behavior that I found interesting: intuition about address spaces, task scheduling, operational jitter, I/O interfaces and performance, and perhaps what would make one programming language better than another. That’s how I found it worth to think about AMMs further.
Not languages, nor computers
One thing that bothered me much early on was whether AMMs were truly distinct from programming languages or the computers that we use.
The question was really: when a programmer thinks about the run-time behavior of their program, are they only able to formulate their thoughts within the confines of the language they’re using to write the program or the computer they’re working with?
I developed my answer to this (negative) from three different sources of truth.
One argument came from linguistics. The question above is really a rephrasing, within computer science, of the question of linguistic relativity (also known as the “Sapir-Whorf hypothesis”): whether language shapes human thoughts. Today, linguistic consensus is that yes, language influences thought, but no, it does not constrain it. People are able to think thoughts outside of their language.
The second argument came from the history of computer science. By and large, algorithmic complexity was well-understood before we defined programming languages and the computing machines to run them. We knew the execution costs of many classes of programs using Turing and Von Neumann machines and the Lambda Calculus, all three being purely mathematical constructs, in the 1950s before any computer was ever built and before the first programming language was invented. In the “chicken or egg” metaphysics of computer science, the AMMs came before the languages and the machines.
The third argument stemmed from empirical observation.
I could clearly see that a programmer trained to write simple C code on an embedded microcontroller had transferrable skills when they learned Python to write programs on a supercomputer. Over and over, I was able to confirm that programmers could transpose their skills over one class of languages and platform to another, without much effort compared to a new learner. They knew one or more AMMs that they could reuse effectively across languages and platforms.
Yet, I could also clearly observe there are multiple distinct AMMs in use side-by-side within a single programming language, and also within a single hardware platform.
In the first category, I found myself studying Haskell again, and determined that Haskell programmers, by and large, use a common AMM which is an abstraction of the MIO runtime system. Under MIO, it is possible to reliably predict the performance of Haskell programs, and develop a strong intuition of how a Haskell program does I/O, what influences its execution externally, etc, even without precise knowledge of the hardware platform.
Yet, MIO is not the only way to design and think about Haskell programs. A group of coworkers developed Clash, a technology which transforms Haskell programs to hardware circuits. When writing Haskell for Clash, the operational semantics are all different, and the rules needed to predict behavior are different too.
Clash defines a separate AMM for Haskell, independent from the one that emerges from MIO, and the intuitions for one are not portable to the other. They are separate AMMs for the same language.
In summary, I incrementally developed an understanding that:
- Programmers use AMMs to write software.
- AMMs exist separately from programming languages, and separately from hardware platforms.
- There is more than one AMM, and AMMs differ in prediction rules and expressivity.
- An AMM can sometimes be used to program effectively across multiple languages, but not all.
- An AMM can sometimes be used to program effectively across multiple hardware computers, but not all.
Programming skills abstract over AMMs, not languages
After I gained more confidence in my understanding of AMMs, I started to think about programming skills: could we use AMMs to more formally and generally identify what separates programmers in skill levels?
To test this, I collected from my peers in academia and in the software industry an inventory of sentences that they use to describe programming skills in specific programming languages, and on specific hardware computers. I then removed the parts of the sentences that referred to specific languages/computers, and replaced them with phrases that refer to the most common properties of the AMMs I knew of (at the time).
The result was a generic description of programming skills independent from programming languages and independent from specific computers.
I published this description online in 2014; to this day, this is by far my most viewed web page, with tens of thousands of views every year. It is cited, reused & translated right, left and center. It appears that folk find this phrasing valuable, across a multitude of programming languages, computers and programming cultures.
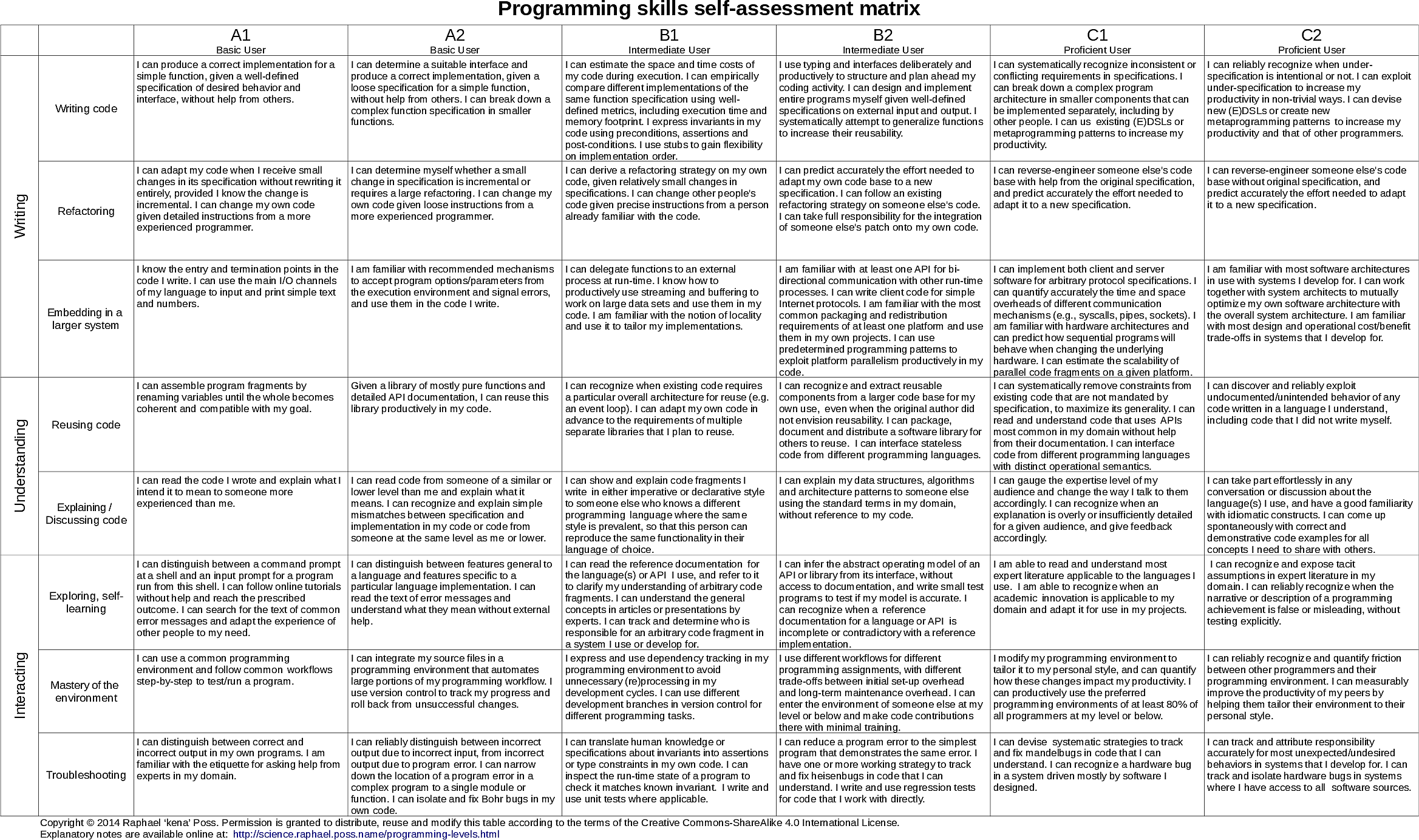
I took this as a confirmation that an AMM-centered meta-understanding of programming skills is valuable somehow.
An AMM inventory
Which AMMs are there anyways?
As I was gaining confidence AMMs were really a thing, the question of identifying them became more pressing, at least to illustrate my points during discussions with peers.
To start, I had found the Van Emde Boas classification (see above) between RAM/PRAM, etc., insufficient. For example, I wanted to explain the following empirical observations:
the operational semantics of C++ programs using POSIX threads, Java programs using JVM threads, and that of Go programs using goroutines could all be reliably described by the P-RAM machine model.
yet, it was very visible that the intuitions about run-time behavior developed for each of these three environments were not easily portable to the others:
- cooperative (e.g. Go prior to v1.14) vs preemptive scheduling.
- memory cost of threads: POSIX is OK with 100s of threads, but not 10000s, Go and Java doesn’t care.
- start latency of threads: Go less than 30µs, Java 50-100µs, POSIX larger than 100µs.
All these aspects heavily influence the design of concurrent algorithms.
At the time (2014), I was able to separate the following AMMs from each other:
| Aspect (rows) / AMM (columns) | C (e.g. C, C++, Python, Rust) | Unix | JVM (e.g. Java, Scala, Clojure) | JS/DOM (e.g. Javascript, Typescript) | BEAM (e.g. Erlang, Elixir) | GPUs (e.g. CUDA, OpenGL, Vulkan) | GHC/MIO (e.g. Haskell) | Go | SQL (e.g. pgSQL) |
|---|---|---|---|---|---|---|---|---|---|
| Units of specification (effective) | Statements / Functions / compilation units or modules | Executable programs | Class methods / Classes / Packages | Statements / Functions | Functions / Modules / Processes | Thread function (on GPU) and coordination code (on CPU) | Expressions / Functions / Packages | Statements / Functions / Packages | Clauses / Statements |
| Program composition, visible at run-time | Sequence points,
function calls,
accesses to
volatile objects |
fork / exec /
sockets / file
descriptors |
Method invocation, use of synchronization primitives | Function calls, callback registration on DOM objects | Function calls / mailbox operations / process spawn | GPU calls on CPU, sometimes thread function calls | Conditionals, pattern maching (destructuring), uses of MVars | Function calls,
goroutine creation,
channel access, uses of
atomic |
CTEs, windowing, sub-queries with an ORDER BY / LIMIT clause |
| Run-time system embeds compiler: enables REPLs and user-defined extensions at run-time | No (yes with Python
and other interpreted
languages with
mandatory eval
function) |
Yes (via cc and
sh) |
Yes | Yes | No | No | No | No | Depends on DB engine, usually no |
| Dynamic program loading at run-time | Limited, via
non-standard APIs
(yes for Python and
other interpreted
languages with
mandatory eval) |
Yes (via mounts) | Yes | Yes | Yes | Yes for code running on CPU, no for code running on GPU | Limited, via non-standard APIs | Limited, via non-standard APIs | Depends on DB engine |
| Base machine abstraction for hardware parallelism | POSIX threads | Processes and threads | Java threads | Web workers | (Hidden) | Hardware thread | Evaluation dispatchers, IO threads | runtime.P objects | (Hidden) |
| Controlled program placement on separate hardware processors | Limited, via non-standard APIs | Limited, via non-standard APIs | Limited, via non-standard APIs | Limited, via non-standard APIs | No | Yes | No | No | No |
| Managed N:M concurrency scheduling | Explicit, via libraries (C) or async calls and workers (C++, Python, Rust) | Explicit, via non-standard tools | Explicit: futures and workers | Explicit: async calls and workers | Implicit, for all processes | Experimental | Implicit, for all reductions | Implicit, for all goroutines | Implicit, for independent sub-plans |
| Program can manage disorderly cancellation of async work, e.g. upon errors | Yes, via non-standard APIs | Yes | Yes (partially) | Yes (partially) | Yes | Yes | No | No | No |
| Ability to define custom memory management in program | Yes | No | No | No | No | Limited | No | No | No |
| Controlled program placement on separate memory domains | Limited, via non-standard APIs | Limited, via non-standard APIs | No | No | No | Yes | No | No | No |
| Memory reachability: all memory use at run-time stems from live objects in program | Yes | No | No (async GC) | No (async GC) | Optional | Yes | No (async GC) | No (async GC) | Depends on DB engine |
| Guaranteed minimum I/O facilities with human user | Yes (stdin/stdout/stderr, and PTYs on unix) | Yes (terminals) | Yes (stdin/stdout/stderr) | Yes (DOM + alert + console) | Yes (io,
sys:log,
sys:trace) |
No | Yes (stdin/stdout/stderr) | Yes (stdin/stdout/stderr) | No |
| Guaranteed minimum IP networking | No, but BSD sockets are prevalent | Yes | Yes | Yes | Yes | No | No, but expecting underlying BSD sockets to be available as API | Yes | No |
| Embedded under the Unix AMM; ability to launch and control sub-processes at the OS level, synchronize with pipes | Yes | Yes | Yes | No | Yes | No | Yes | Yes | No |
| I/O synchronization | Controlled by program, inline & blocking by default, async I/O available via non-standard APIs | Controlled by program, inline & blocking by default, async I/O available via non-standard APIs | I/O threads, non-blocking | Inline & blocking (but can be deferred / batched via judicious chaining of async calls) | I/O threads, non-blocking | I/O threads, non-blocking | I/O threads, non-blocking | I/O threads, non-blocking | Inline, blocking |
| External intervention while program is running, without stopping program | Breakpoints (blocking) ptrace (non-blocking) | ptrace (non-blocking), signals | Breakpoints (blocking) | Breakpoints (blocking) | Breakpoints (non-blocking) | Breakpoints (blocking) | Breakpoints (blocking) | Breakpoints (blocking) | No |
| External observation while program is running | Watchpoints, profiling, ptrace | ptrace, profiling | Watchpoints, profiling | Watchpoints, profiling | Watchpoints, profiling | Watchpoints, profiling | Tracepoints, stack dumps, profiling | Profiling, stack dumps | Tracepoints, profiling |
Note: I consider .NET to provide yet another AMM, close but not equivalent to, that of the JVM. But I did not (and still do not) know much about it, so I couldn’t include it in this table.
AMM communities
AMMs define software ecosystems.
They define “cultural boundaries”: it’s easy for a programmer who knows an AMM to transition to a different language whose semantics project well into the same AMM, and it’s harder to cross AMM boundaries.
And so it was interesting to me to wonder: “when do AMMs appear? When does a programming language designer push for a new AMM, and when can they slip into the shoes of an existing community?”
While building the table above and studying PL history, I discovered that language designers come in three groups:
- machine-first designers, who start with one or more hardware platform that’s sufficiently different from everything that was done before that it needs a new AMM, and often a new programming language to program it.
- second-language designers, who assume the existence of some machine/language ecosystem, adopts it and simply adds new abstractions / expressivity on top.
- AMM-first designers, who are interested to control the way programmers think first (usually, due to some idea about how this will result in better software quality), and who merely think about hardware diversity as an inconvenience that needs to be hidden from programmers.
Most common: second-language ecosystems
Second-language ecosystems are the most prevalent nowadays. Language designers in this category actively reuse the same platform abstractions as a well-known, understood AMM, and explain (more or less explicitly) that programmers in their language can work with the same AMM in mind.
For example, the Rust documentation does not define its own AMM and the community largely understands that Rust uses the same AMM as C/C++.
Likewise, the TypeScript docs do not define a custom AMM and the community understands it maps to the JS/DOM AMM.
Elixir docs are more explicit and spell out clearly that Elixir programs use the same AMM as Erlang/OTP.
Machine-first ecosystems: innovation by tinkering
Machine-first designers used to be extremely common in the period 1960-1990. They are, in fact, responsible for the explosion of AMMs and programming languages until the late 1990s. Many of these AMMs have since disappeared into obscurity, and only a few remain in active use.
The most visible artifact of that period, of course, is the unix AMM and the various C/C++ AMMs.
Despite what the table above suggests, there’s not just one C/C++ AMM; instead, there are “dialectal” differences in AMMs used by C/C++ programmers. For example, certain ways to think about the machine and to algorithmic choices are different depending on whether a programmer targets an embedded system without virtual memory and threads, or a multi-computer network.
However, by and large, the majority of programmers who write C/C++ and other related languages (incl. Python, Rust) use a “common dialect” AMM with threads, shared memory, per-thread private storage, a heap/stack split, unified code/data addressing, raw access to pointers and bytes in memory, a private address space, a single filesystem and file descriptors / sockets for I/O.
Post-1990s, the only widely-successful machine-first design stemmed from the hard industry push towards accelerator-based architectures, especially programmable GPUs. This resulted in unique AMMs fully separated from what was prevalent at the time. We’ll discuss this more below.
Constrained programming: AMM-first designs
Some language designers are very intent on controlling the way programmers think about platform semantics, and so work actively to define and document their own AMM, carefully to hide whichever semantics are available in the underlying hardware platform where programs run.
They do this, generally, out of three types of concern:
they have a strong desire to ensure that all programs can be portable across a wide diversity of hardware platforms. For this, it was paramount that no programmer could ever make specific assumptions about the hardware platform.
For example, this happened with the JVM and JS/DOM.
they have a theory that a constrained AMM will make it possible to prove (or guarantee) software correctness / stability / quality / compositionality for a large class of programs.
For example, this was the reason for the definition of SQL. Later, the Erlang designers did this too with BEAM.
they have some theory that a different AMM will guide programmers towards simpler solutions for common programming tasks, or that the AMM will make it easier to maintain / extend programs somehow.
The Go designers did this, regarding everything related to concurrency, by restricting concurrent programming patterns to those allowed by Tony Hoare’s calculus of Communicating Sequential Processes.
The Haskell situation is a bit different. The original innovation of Haskell was to project programs into a graph reduction machine using term substitution, and that clearly defines an AMM that is quite different from everything else at the time it was invented.
However, over time, pragmatic Haskell programmers also needed I/O, networking and other features! So the Haskell ecosystem gradually developed an AMM with these features by abstracting from the most commonly used implementation, GHC/MIO, which is constructively embedded inside the C/C++ and Unix AMMs and so inherits some of their features.
AMM adequacy and success
Programmers target AMMs, not languages or machines
It sounds almost trite to spell out that most programmers expect that their programs can run… on a real computer.
In fact, the majority of software is written with that expectation, and a great deal of software is optimized by programmers to run well on a particular class of computers.
And as we’ve seen above, they do not (nor would like to) think about specific hardware parameters, and so they wish to abstract over hardware, but they also usually want to ensure their programming skills transpose across multiple programming languages.
In other words, the ability of a programmer to do their job well is largely dependent on their ability to utilize hardware capabilities in their programs, and predict program behavior, using an AMM as thinking tool.
Parallel programming is hard
By far, the most significant event in the evolution of AMMs in our computing history was the loss of Dennard scaling on single processors, and the mandatory gradual move to multi-core platforms.
Where prior to year 2000, parallel programming was an activity restricted to a few practioners with unusual computing needs, after ~2005 it became everyone’s problem. And through the period 2000-2010, the software industry as a whole had to scramble around the realization that they did not possess good AMMs to program parallel hardware effectively.
This resulted in a flurry of research projects and more-or-less successful technical developments. Besides ATI’s and NVidia’s efforts, which eventually culminated in the emergence of the accelerator architecture and its “Compute GPU” abstraction as the dominant AMM, there was a myriad of smaller-scope projects with various degrees of funding and programmer interest.
For example, I am personally fond of Chapel, which provides a simple AMM over distributed compute nodes (a strictly more powerful AMM than P-RAMs).
In 2015, I organized my thoughts around the diversity of AMMs for heterogeneous parallel platforms and captured them in this presentation to a research seminar.

This was also the time I was toying with my own concrete proposal for a more intelligent Unix model to run on many-core computers. This was also well-received, and this article was accepted at a relatively prestigious journal: Poss, R.; and Koning, K. AM3: Towards a hardware Unix accelerator for many-cores. IEEE Trans. Parallel Distrib. Syst., 26. October 2015. DOI 10.1109/TPDS.2015.2492542 (preview).

Natural tension: control vs guarantees
Hardware is messy. More specifically, hardware behavior outside of the CPU/memory/disk trifecta is extremely hard to model accurately. This includes things like external I/O (e.g. networking, USB, touchpads), internal I/O (e.g. cache coherence, memory interconnect), energy usage, etc.
So any programmer who cares about these things needs to hold an AMM in their mind with a great(er) deal of complexity. They either need to find an ecosystem with an existing AMM with all the facilities they need, or develop their own AMM with more specific assumptions about their target computer, i.e. tie their personal AMM to one physical machine.
When they do this, they often reduce their ability to predict program behavior accurately when the program increases in complexity. They also lose the ability to obtain predictable behavior when the program runs on a different computer (if it runs at all).
Conversely, a programmer who cares about engineering costs over time, including reuse and portability, will likely constrain themselves to thinking their software in the terms of an AMM that has powerful prediction abilities and strong compositional semantics over a variety of hardware platforms.
This is commonly achieved by restricting the number of ways that programs can be written, to a fixed subset of software patterns with predictable behavior.
Fallacy: control and guarantees are not either/or
A common fallacy in software engineering is to think about AMMs as existing on a linear spectrum with “more control, less guarantees” at one end, and “less control, more guarantees” at the other end.
Something like this:
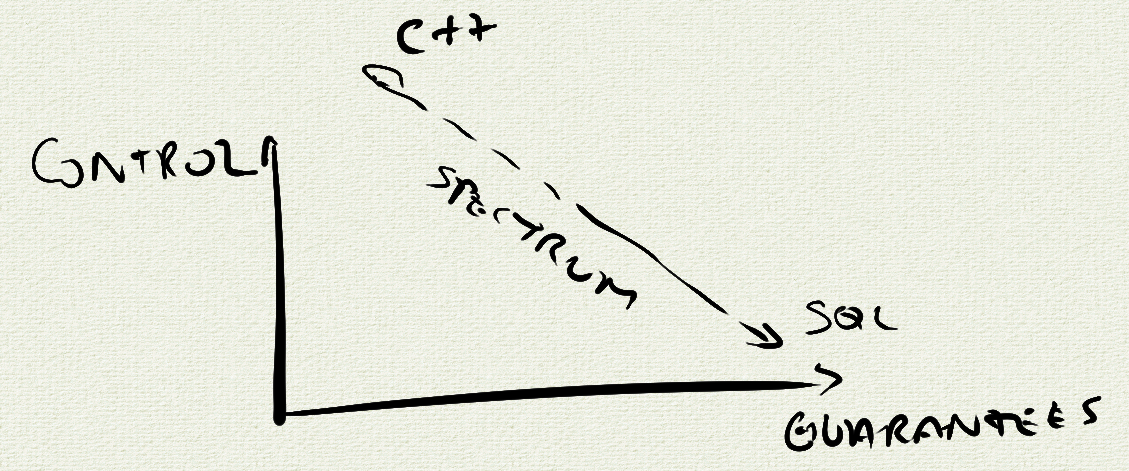
However, the reality is that this spectrum is not linear. Even though there is a general inverse correlation between these two dimensions, certain AMMs provide more control at equal level of guarantees.
For example, it is possible to model, then exploit in programs, support for thread-local storage (TLS) in those hardware platforms that provide it, without losing the ability to reason about deadlock freedom, object lifetimes and freedom from race conditions. This is possible as long as this model has restrictions on the lifetime and sharing of references to TLS, such as is achieved with Rust’s lifetime and reference sharing semantics.
So extending an AMM with modeling power over hardware facilities does not necessarily result in loss of guarantees. Conversely, at a given level of guarantees on software correctness / cost / stability / maintainability, certain AMMs have more modeling power than others. Arguably, they are “better.”
It is thus more useful to think about AMMs as points on a two-dimensional space, with a Pareto front of maximally useful AMMs on this control/guarantees space. Something like this:
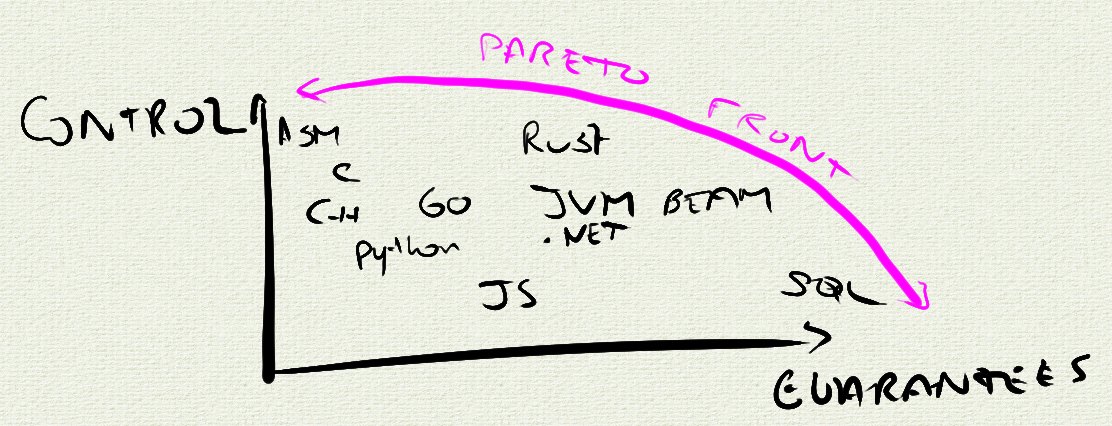
Rust pushed the Pareto envelope
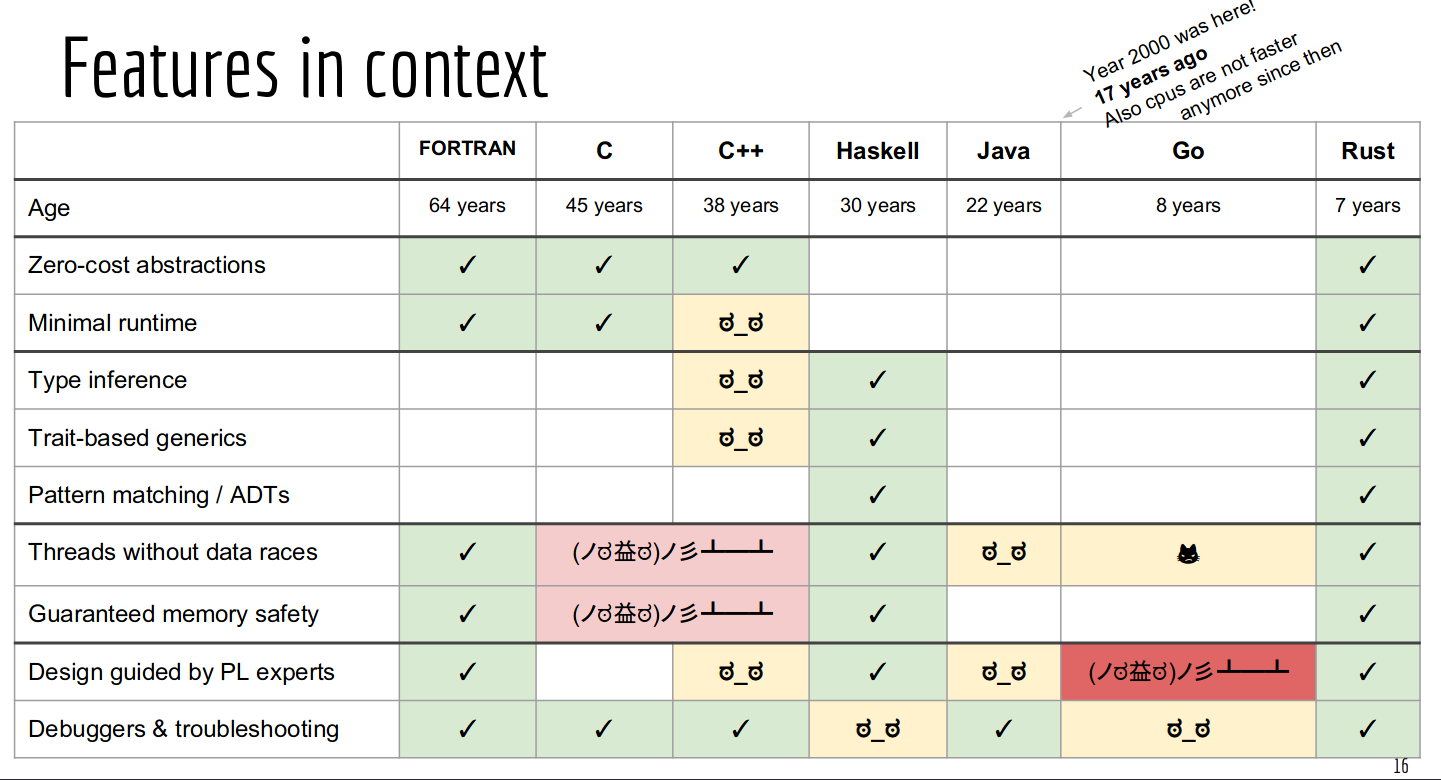
Rust’s designers chose an interesting position in the design space of programming languages: for most simple programs, it enables programmers to reuse the C/C++ AMM and thereby exposes access to the largest diversity of I/O interactions; and yet, it also moderates access to memory and concurrency (using its lifetime and mutable reference checks) in a way that makes it easier, cheaper and more reliable to write correct and more stable programs.
As a “cherry on top of the cake”, Rust was designed with functional ergonomics: it presents to programmer the expressivity of a modern functional language, with a modern type system.
This combination of advanced ergonomics while offering an AMM that provides intuition about hardware behavior that’s at least as good as C’s AMM with more guarantees on program correctness, was absolutely revolutionary.
You can find a few more of my thoughts on Rust’s unique position in the AMM bestiary in this introduction to Rust I gave to a research group in 2017.
Benefits & what comes next
I have already integrated this understanding in my mentoring and my teaching practice. I am now able to explain that what makes certain programming problems “hard” or “interesting” is not related to oddities in hardware or programming languages, but rather to the way programmers think about machines, i.e. the properties of their AMMs.
This makes me able to connect related software challenges across programming language boundaries, or to recognize when similar-looking programs in different languages have, in fact, extremely different semantics.
It also makes me able to estimate how much time or effort it will take me to learn a new technology stack or programming language: if I can track its ancestry and design principles, I can estimate its conceptual distance to AMMs I already know.
It also makes me able to estimate whether an already-written program will work well on a new computer, with or without translation to a different language or machine instruction set (ISA), depending on what I know of the AMM that its programmer likely had in mind when the program was written.
That said, I also think that our “good” AMMs today (in 2022) are also too complex. In particular, I think the problem of finding good AMMs for parallel programming, AMMs that are both easy to teach, easy to reason about and powerful enough to predict performance accurately, is still an open topic of research. So I’ll continue thinking about that.

References & further reading
- Jeroen Voeten, On the fundamental limitations of transformational design, ACM Transactions on Design Automation of Electronic Systems, Volume 6, Issue 4, October 2001, pp 533–552, DOI 10.1145/502175.502181.
- Peter van Emde Boas, Handbook of theoretical computer science (vol. A), chapter Machine models and simulations, p. 1-66, MIT Press, 1990, ISBN 0-444-88071-2.
- Poss, R.; and Koning, K. AM3: Towards a hardware Unix accelerator for many-cores. IEEE Trans. Parallel Distrib. Syst., 26. October 2015. DOI 10.1109/TPDS.2015.2492542.
- Rust for functional programmers on this site.
 is an entrepreneur who occasionally publishes field notes on systems, leadership, and the messy edge between technology and people.
is an entrepreneur who occasionally publishes field notes on systems, leadership, and the messy edge between technology and people.
Comments
Interested to discuss? Leave your comments below.